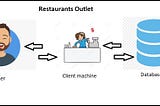
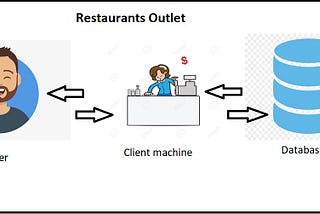
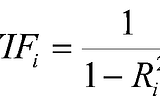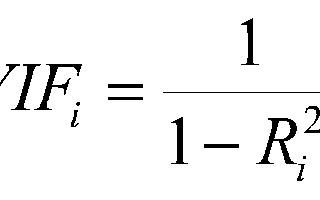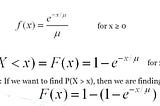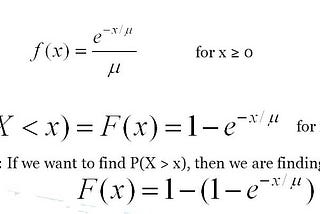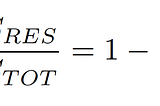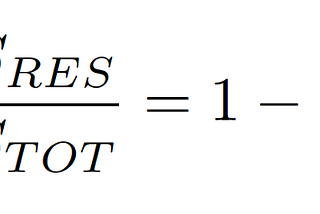Saurabh GuptainAnalytics Vidhya2-Tier and 3-Tier Database ArchitectureDatabase Architecture is a design for a Database Management system. There are three types of design for DBMS 1- Tier, 2-Tier and 3-Tier.2 min read·Nov 1, 2021--1--1
Saurabh GuptainAnalytics VidhyaVariance Inflation Factor (VIF)We have always heard about Multicollinearity whenever we talk about the regression model but we never wonder ways to check this.2 min read·Jul 5, 2021--1--1
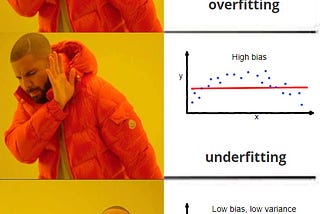
Saurabh GuptainAnalytics VidhyaOver-Fitting VS Under-FittingLet’s start with discussing the terminologies used in the image.3 min read·Mar 26, 2021----
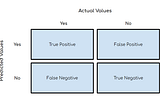
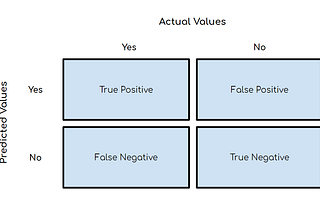
Saurabh GuptainAnalytics VidhyaPerformance MetricsMetrics are used to evaluate the performance of Machine learning algorithms, classification as well as regression algorithms. We must…4 min read·Mar 16, 2021----
Saurabh GuptainAnalytics VidhyaDistributionsWe are going to discuss some distribution functions. We will see their properties and try to understand them with basic examples.3 min read·Mar 2, 2021----
Saurabh GuptainAnalytics VidhyaCorrelation Status: It’s ComplicatedThis article is all about “relationship”. Relationship between two independent variables. How those variables are related and how strongly…4 min read·Feb 15, 2021----
Saurabh GuptainAnalytics VidhyaAdjusted R-Squared: Formula ExplanationAs the name suggests, Adjusted R-Squared is an adjusted version of R-Squared. The question arises why we need to adjust R-Squared.3 min read·Feb 8, 2021----
Saurabh GuptainAnalytics VidhyaR-Squared: Formula ExplanationWe all must have seen these terms whenever we are working on some regression model. We all know the definition, we all know the usage, we…3 min read·Jan 25, 2021----